

Automated Document Classification

Integrate Accurate Data More Quickly with Automated Document Classification and Separation
Nearly all data capture projects suffer because of challenging data sources. It does not have to happen to you.
You can easily use machine learning algorithms and rules-based logic to organize the chaos of semi-structured and unstructured documents. We have 3 unique document classification methods that put you in control.
And you do not have to be a data scientist to build a training set with Grooper. Discover how to use document classification models with transparent features that you train and control.
3 Techniques to Solve Classification Problems:
We call our classification ‘ESP’ because it is almost like a sixth sense. The Grooper ESP Auto Separation Engine classifies and separates documents at the same time, based on page’s content.
And the beautiful part? All training is performed in a visual editor so you see in real-time how documents will be processed.
Transparent A.I. removes any mystery as to how the machine learning models are functioning and how the supervised classification works.
Here are 3 tools you can use in Grooper document classification software to understand and classify documents and content:
1. Lexical Approach
Natural language processing looks at the text of the whole document to understand context using TF-IDF (which is term frequency – inverse document frequency).
This is a training-based approach where examples of a document are used to classify new documents.
Multiple document types may be combined into a single group of documents.
Learn much more about our lexical classification in our Wiki.

2. Rules-Based Classification Approach
Find unique key words or features that identify a document, like a title, section heading, or any specific data element.
Grooper uses “positive” and “negative” extractors to identify document type.
Positive extractors positively identify documents and negative extractors prevent a document from being identified as a particular type.
Check out our Wiki to learn more about our rules-based classification.

3. Visual Approach
Computer vision looks at the visual structure of a document without having to read from OCR.
Image data is used for automatic classification instead of text.
Visual classification can be run during scanning to save time by rapidly sorting out structured forms from other document types.
Learn more about visual classification in our Wiki.
Classify documents faster and easier than ever before!
How Machine Learning Classifies Documents and Datasets Like Humans
Why is it so hard for machines to understand documents, and to classify them?
In this infographic, you will see how Grooper overcomes the limits of traditional OCR by using machine intelligence to understand documents like a human.

What is ESP Auto Separation?
It is the ideal solution for the most complicated document classification and separation challenges. By combining classification logic with extracted page data, it classifies and separates documents at the same time.
This means that the worst document nightmares are no problem for Grooper. Whether the documents are structured, unstructured, disorganized, or mis-labeled, Grooper has the tools to help you get around these problems.
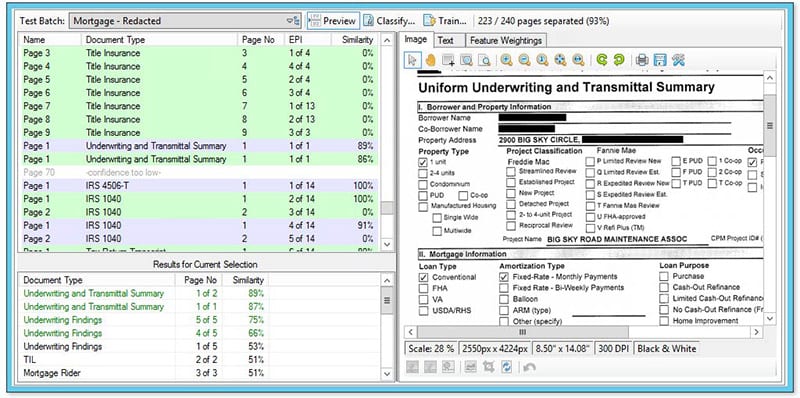
Overview: Document Training Based on Content
Users train document examples in a visual interface to see how the ESP Separation Engine interprets the content of each page. Then, the resulting classification model and grouping of pages is simulated so there are no surprises at run-time.
Any errors from pages that were incorrectly organized or added by mistake are easy to spot and correct.
Sit Back and Watch the Automatic Document Classification
Simply give Grooper document training examples and watch it learn the right document type for each one based on a machine learning algorithm.
When batch testing large volumes of documents, any with low confidence scores are be flagged and sent to a queue for an operator to provide more semi-supervised training.
Photo and Image Classification
Classify photos through Grooper’s integration with A.I. cloud services. Use the Azure Computer Vision API to return words (or tags) that describe the content of a picture.
For example, you can use it to quickly find and read text within images. Or, using supervised classification, you can extract and tag documents by using information from text found within pictures.
The extracted data is used to to classify image files or photos within documents, or to add metadata.
How does this help you? One way is by reducing risk and ensuring compliance through creating workflows that will move documents or images with particular or sensitive content to a secure place.

Document Classification FAQs
What Is Document Classification?
Document classification is the process of using a document’s content to assign category or class labels and easily organize, manage and find data or documents in information science, computer science and library science.
What are Examples of Document Classification?
One real-world example of document classification is classifying invoices based if they have line-item tables or simple totals.
Other examples include: categorizing Explanation of Benefit (EOB) documents based on insurance company / payer, or analyzing emails based on spam phrases to classify them as spam or not spam.
In the energy industry, an example of document classification is grouping oil and gas leases by risk level based on title defect information in the documents. Low-risk leases will then be purchased.
How Does Document Classification Work?
Document classification can be done either manually or through automation, by using machine learning (ML) algorithms and natural language processing (NLP). The types of documents that can be classified include text documents, scanned image documents, electronic files, etc.