Image Processing Software
Boost Work Efficiency Through Superior Image Processing
Image processing software improves document images displayed to users throughout data capture workflows, gets best-in-class OCR, and creates beautiful documents for permanent archival.
A robust image profile builder provides seamless and immediate in-app feedback for testing results.
How Does Image Processing Software Improve OCR?
Good OCR (optical character recognition) starts with images that are only made up of text, and free of non-text artifacts. Grooper has over 70 image processing features to ensure you get distraction-free OCR.

Now let’s look at a few examples to show in detail what Grooper’s image processing is doing:
Safe and Clean Halftone Removal
Dithering and other halftone patterns are a direct result of legacy image processing software poorly converting color images to black and white.
These things must be eliminated to prevent massive errors in OCR technology results, particularly with punctuation like periods and commas.
Before Halftone Removal:
Halftones completely surround text we would like to capture. OCR stands very little chance at seeing this text.
After Halftone Removal:
Grooper finds dithered patterns and safely removes them without eliminating punctuation that is close to letters on the page.

Seriously Brilliant Border Removal
Borders have commonly been very tricky to remove when the black region does not extend all the way to the edge of the page.
Grooper understands how to address a variety of uncommon border scenarios to cleanly remove them.

Photoshop-Like Inpainting
You work with full-color documents every day. So why should not your digital image processing software do the same, no matter the image format you are using?
This is no problem for Grooper intelligent document processing. It is object removal and editing breaks out of the realm of black-and-white processing with full color recognition and editing.
Use this feature to digitally restore damaged or unknown parts of an image using information from nearby pixels.

Imagine the benefits of the best document image software in your organization. Let us know how we can help you.
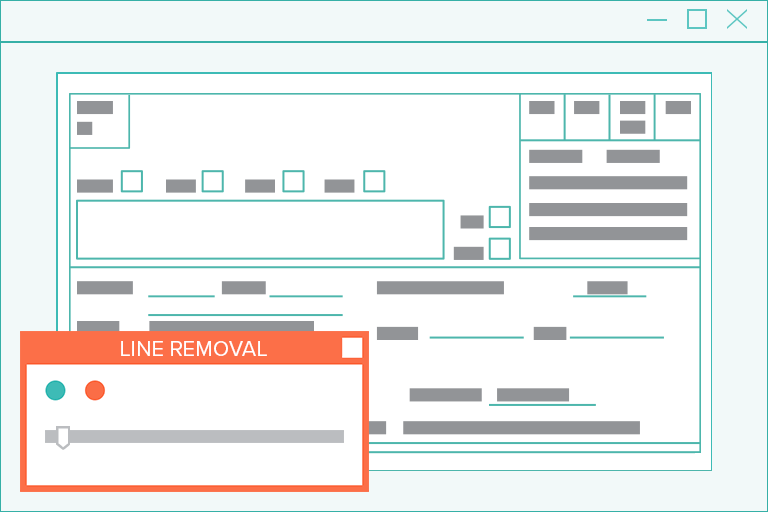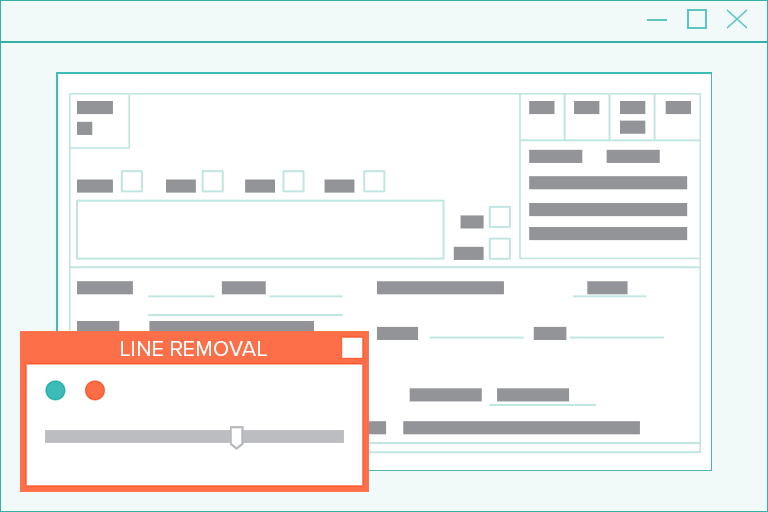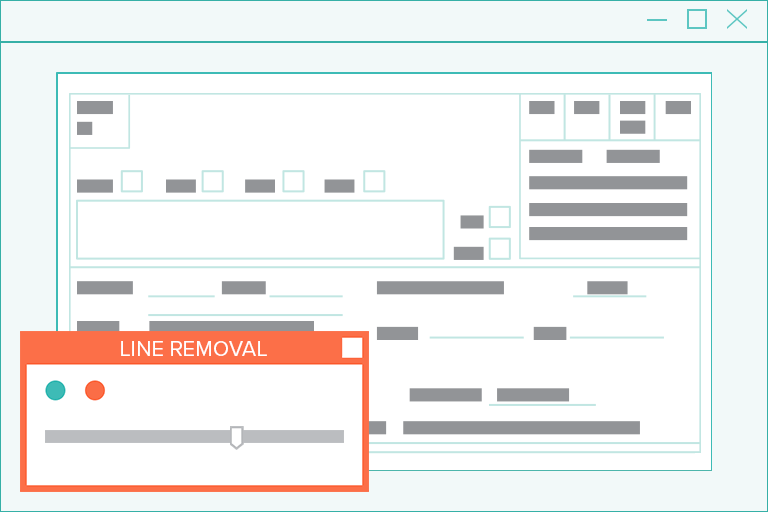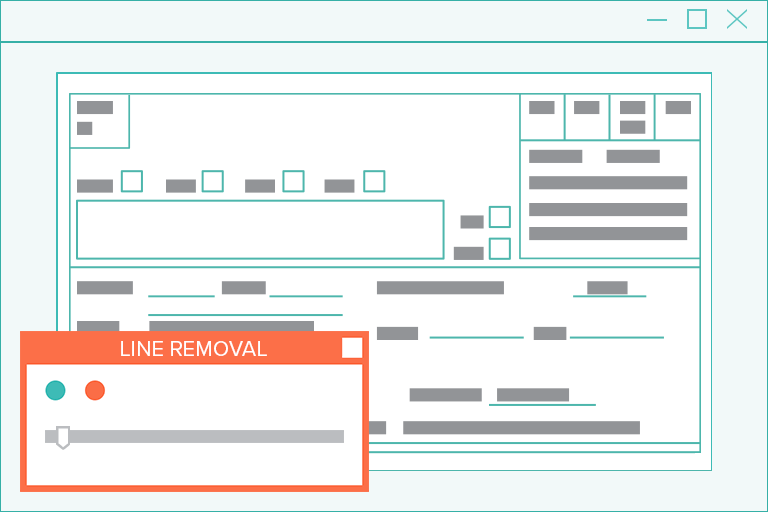
Image Processing Software: Pixel-Perfect Line Detection & Removal
For humans, lines are needed to provide visual cues that make documents easier to read. For example, lines of all sizes are common and frequent in forms, table structures, and pages with fill-in-the-blank boxes.
However, these lines (particularly the short, vertical ones) are commonly and mistakenly read by OCR engines as letters or numbers.
But with superior image software, built-in computer vision erases these lines with ease…