

OCR Technology Software

Learn about OCR software that simply works better.
How to get Perfect OCR
Want to know the secret? Remove everything that is not text – it makes the OCR engine’s life so much easier.
Grooper does this through industry-first image processing software and out-of-the-box configurations designed for the task.
The best part is that these document capture tools will not alter the original version of the image that you want to permanently retain. Whether you have paper documents or electronic, Grooper provides the best results in image processing and capturing text.
What is the best OCR software?
We get asked that all the time. OCR alone is far too inaccurate. The answer is combining Grooper’s image processing and recognition tools with one of many off-the-shelf engines such as Transym 4/5, Tesseract, Azure, ABBYY, Prime, etc. Already have an ABBYY or Prime subscription? Import it into Grooper!
(Not sure what Grooper is? No problem. Learn more about Grooper intelligent document processing.)
How Grooper Prepares a Document Image for OCR:

How Our Patented OCR Technology Ensures Accuracy
No matter how clean and pristine document images appear, OCR scanner software still struggles to collect accurate text. Text in images, in multiple columns, and in different font sizes all contribute to bad character recognition.
Another cause of inaccurate data capture is that recognition engines process pages from top to bottom. (Hint: A better approach is OCRing select areas of a page and combining the results together.)
However, Grooper uses 2 highly unique and patented technologies that ensure the highest recognition accuracy:
- Data element profiles and overrides for dynamic optical character recognition based data extraction – Patent #10,740,638
- Systems and methods for optical character recognition – Patent #10,679,089
Grooper’s patented OCR synthesis engine intelligently performs multiple passes on different portions of a document image. Results are grouped together as a single unit, providing highly accurate text results.
In a lab OCR accuracy test, Grooper accurately captured 99.91% of text. Using OCR alone on the same data set proved half as accurate.

Cheat Sheet: How to Select the Right OCR Software
There are many things that make some OCR software much better (and help you save more time and money) than others.
In this free Cheat Sheet, you will discover the most important qualities to look for in the best OCR software, such as:
- How some OCR software uses letter matching to get more accurate recognition results
- 3 Vital document imaging technologies used by the best OCR platforms
- How 15 image processing features boost OCR from average to excellent
- Why even a slight increase in data accuracy can eliminate countless hours of manual data entry
Download Now:
Synthetic OCR – 6 Tools that Guarantee Accurate OCR Technology

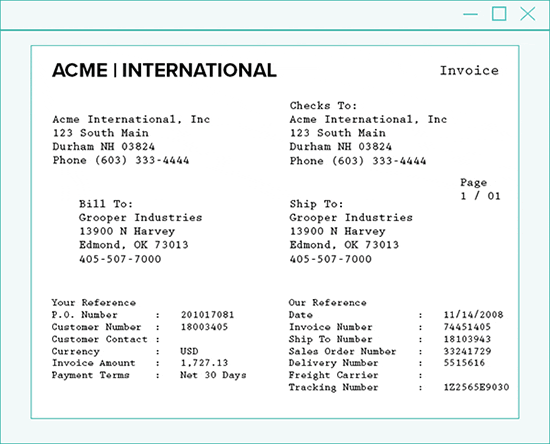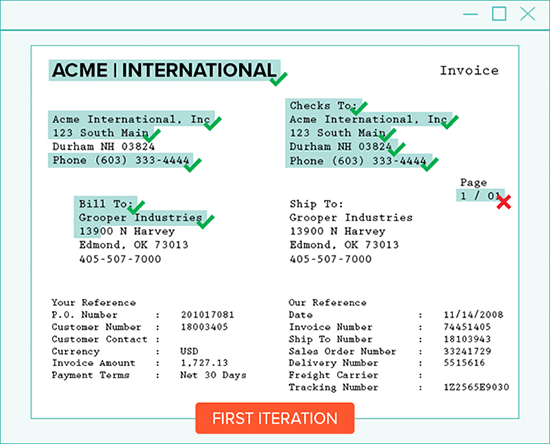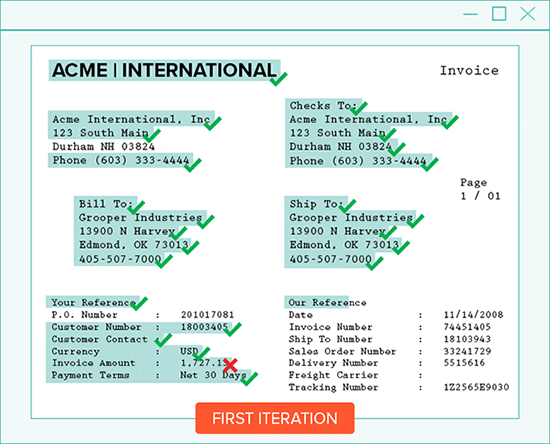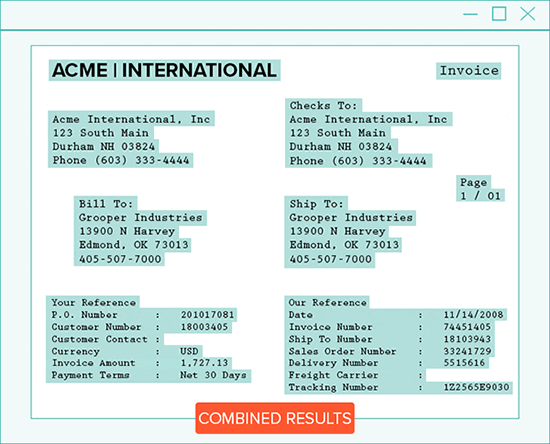
#1: Iterative OCR – Capture Missed Text
Iterative OCR captures text missed on the first pass.
In order to get the rest of the text, Grooper runs OCR multiple times. On each pass, recognized text is dropped out of the document image. The recognition engine finds any remaining text.
Because each new pass has less distractions, finding missed text is easier.

#2: Cellular Validation – Capture Columns of Text
Multi-column layouts present a unique challenge for OCR, especially when columns of text are offset, or have different fonts, or font sizes. These are typically documents like invoices and purchase statements.
Standard recognition software will fail on at least one of the columns of text. Because Cellular Validation splits an image into a grid, each area is processed independently.
The result: industry-leading accuracy for reading and processing documents.


#3: Bound Region Detection – Capture Text in Boxes
A bound region is a page section which is bound on all sides by lines. Grooper’s Bound Region Detection changes the order of character processing by starting first with the text inside of boxes.
This ensures that content outside of text boxes does not cause confusion when reading content inside text boxes.
Extracted text from each box is removed from the document image before performing full-page OCR. Because the location of the text boxes is understood, all text is intelligently joined back together.


#4: Segment Reprocessing – Automated Re-Processing
Because Grooper understands the layout of text on a page, groups of data are viewed as segments.
Grooper independently re-runs recognition on low accuracy segments of text until the best accuracy is achieved.

#5: Layered OCR – Capture Multiple Fonts and Handwriting
A document with multiple fonts makes accurate character recognition tricky. But Grooper overcomes this by using a different engine for each font type and combines the results.
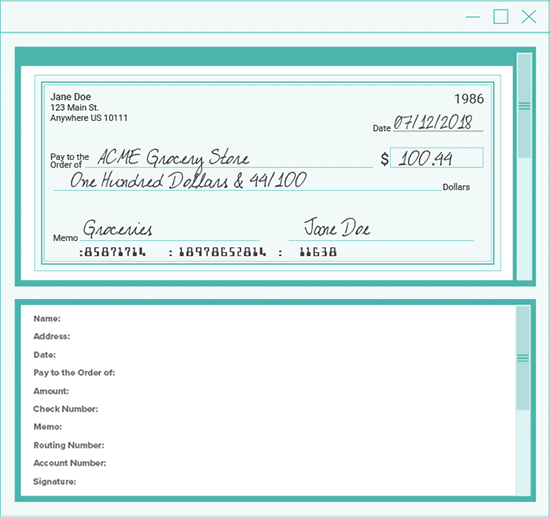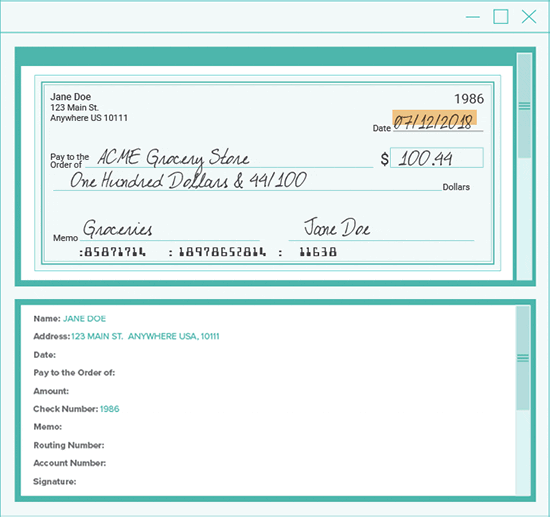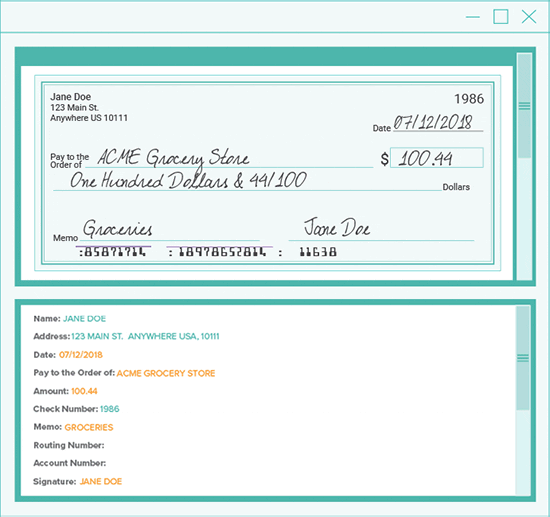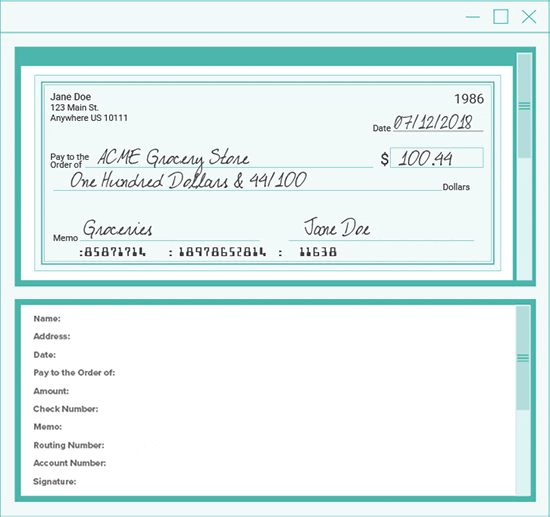
One example of a document with mixed print types is a check, which includes standard text fonts, OCR-A or -B, MICR fonts, and handwriting.
Because some engines read certain fonts better than others, it makes sense to use the right tool for the job.
Grooper makes check processing a breeze.
Another use-case for this feature is label repair. Grooper repairs text in field labels for greater accuracy and simpler data extraction.

#6: Font Pitch Detection
Different fonts make life easier for humans by showing different sections of a document, or helping a company look different from its competitors.
But they make recognizing text more difficult for all OCR technology as different fonts have different amounts of space between characters. If an OCR software has trouble with this, many words and data are captured incorrectly.
However, Grooper’s Font Pitch Detection feature looks at the width of each character and the space around them in order to learn the correct way to recognize and capture data accurately.
Intelligent Spell Correction
Powered by Atomic RegEx, Grooper performs corrections to fix some pretty ugly stuff. And what is the secret to making this work? A few tools, like K-Means Clustering, text removal, and text correction engines.

What Spelling Errors Does Grooper Correct?
- Simple capture mistakes in strings that do not match words in a standard dictionary
- Human-generated typos on documents
- Word splitting – insert spaces where OCR falsely jammed multiple words together
- Delete strings of characters that are not numbers or letters, like strings that resemble an attempt at censorship, like “$#@! ^&*”
- Repair numbers, such as prices, where overly-aggressive image cleanup mistakenly removed punctuation
How to OCR a PDF Document
PDF is the most widely used document standard in the world. Because there is no standard for generating a PDF, capturing text has varying levels of difficulty:
- Some PDFs are purely text-based (easy to capture from)
- Others are just document scans in PDF format (difficult)
- Others PDFs have combinations of the two scattered throughout pages (most difficult)
PDF documents have a fair amount of text capture challenges.
How to Get Text off of PDFs:
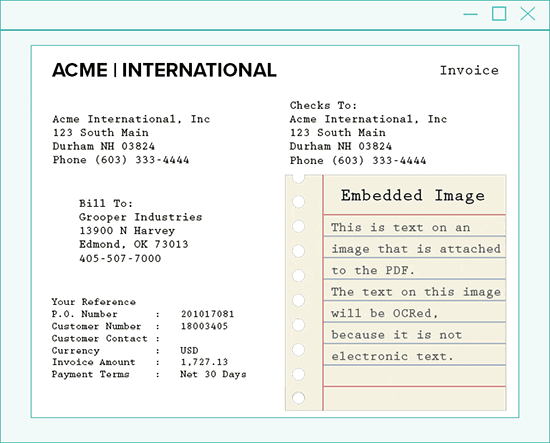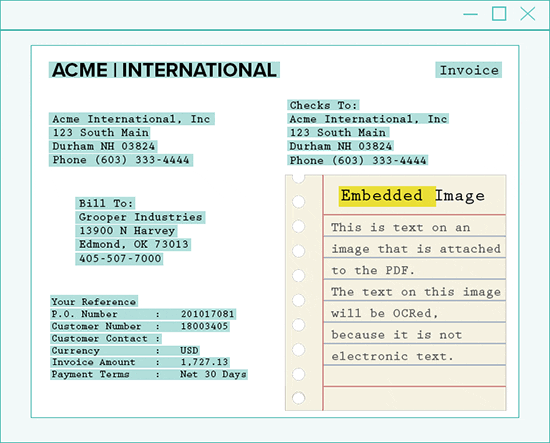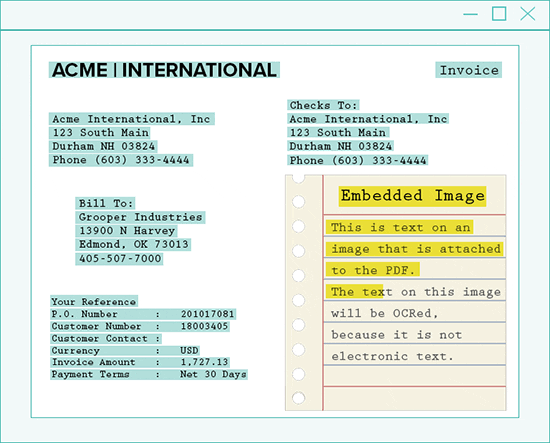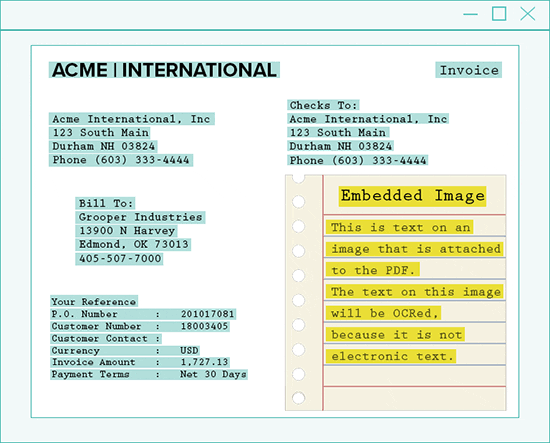
Grooper looks at each page within a PDF and places the page into one of three categories: image-based, text-based, or mixed-content.
By doing this automatically, specific rules and processing methods make text extraction easier.
Then, each page is handled accordingly:
- Process PDF pages that have a single image covering the entire page as image-based pages
- If a PDF contains no images, extract only the raw text-behind the page
- For mixed-content pages, extract each image to a temporary image, process the image, and merge the results with the native text

Get Our Free Guide and Explore Grooper’s OCR Further!
Did you know that many OCR solutions can’t solve your everyday document capture problems? So what separates the modern OCR from legacy solutions?
Get our guide and you will discover 7 very important differences that will transform your projects from bust to boom!
Get the Guide:
Additional Tools

Trainable OCR
Grooper OCR is trainable. The engine supports training custom and difficult font formats.

Performance Balancing
Grooper’s “Run Speed” option provides control to achieve the ideal balance between accuracy and performance. Lean more how to speed up your OCR here.

Language Support
Grooper recognizes 268 distinct languages and 523 regional cultures. Language detection interprets dates, times, currency names, numeric formats, and more.

Electronic Text
Grooper avoids OCR altogether when dealing with original text-based files like Word, Excel, and Text PDFs. Instead, Grooper pulls complete and perfect text directly from the file.

Watch: Add ChatGPT to Your OCR for Maximum Data Recognition
Leverage the latest AI advances to get OCR results that are a cut above. We will show you how to use ChatGPT with your OCR software to extract and improve the data from your business documents.
Discover 4 new technologies:
- How to use artificial intelligence to improve bad document scans.
- How to use the latest and best OCR engines – without the cloud.
- How to talk with your documents using ChatGPT (and other GPT models) to easily get data that was never before possible.
- How to quickly create the most efficient data workflows
For every day that you are not using the newest AI, you could be falling behind your competitors. Get the video now:
OCR Frequently Asked Questions
What is OCR technology?
OCR stands for optical character recognition technology, and businesses and people use it to find and get words or numbers off pictures, like photos or scanned documents.
How does OCR work?
OCR technology analyzes pixels on an image and translates those pixels into text.
After the text (printed or handwritten) is extracted, it is converted into a machine-readable format where the data can be injected into business intelligence platforms, content management systems or enterprise resource planning systems.
What is OCR used for?
Once the OCR data is in business systems, it is used to improve search abilities, help businesses make better decisions, and to understand internal operations (or how third-party vendors operate) better.
Generally speaking, the more document-trapped data that an enterprise has, the more that it can benefit from OCR technology.
How good is OCR accuracy?
Surprisingly, OCR by itself is only about 49% accurate. But OCR document software employ many technologies and methods to increase recognition accuracy.
These technologies include computer vision, image processing, artificial intelligence (AI), and intelligent character recognition (ICR). Some of the methods that OCR uses include zonal OCR and synthetic OCR. Learn more about OCR accuracy.