

Natural Language Processing

Capture Information from Sentence Flows
With Grooper Natural Language Processing, find paragraphs, sentences, or other language elements in your documents that convey specific meaning.
Supervised machine learning makes training easy and transparent. Powerful n-gram analysis ensures reliable interpretation – regardless of wording differences.
Grooper reads paragraphs and sentences in documents just like a human. Leverage powerful machine understanding that accurately recommends correct values from the body of documents by considering the surrounding flow of human language. What is Grooper?
Natural Language Processing Examples:

- Language Element Recognition:
- Find all paragraphs or sentences in a document.
- Language Element Classification:
- Decide if a contract has a non-solicitation clause.
- Document Flow Detection:
- Extract ‘Monday, May 27, 2009’ across multiple lines.
- Context-Based Data Capture:
- Decide if a date value is the Maturity Date or the Loan Date.
- Powerful Language Parsing:
- Distinguish “SW ¼ of the NW ¼” from “SW ¼ and the NW ¼”.
Tackle your most difficult problems in natural language processing. Power through large amounts of documents and data quickly and efficiently.
Why This NLP Processing Method?
Working with legal documents like contracts or leases? This technique makes it possible for you to find specific provisions or legal descriptions and then break them down into the data you need. Abstract any data more quickly – find dates, individual tracts of land, legal clauses, and more.
Now you do not need custom development or multiple data science tools. Fuel your workflows with production-quality results.
Grooper natively processes text as n-grams and via porter stemming in addition to supporting configurations that implement more complex NLP processing methods such as:
- Sentiment NLP analysis
- Part-of-speech tagging
- Named entity tagging
- Feature-based tagging
The main difference between a standard NLP library (like the Stanford Library) and Grooper is the use of NLP throughout the product, not just as an add-on. NLP and other advanced ML / AI functionality is embedded throughout the solution.
Although the learning curve is high, it isn’t too much more than other products.
Grooper’s approach to image and document analysis is not comparable to any other in the space. The intelligent analysis is fantastic and reduces man hours with growing return on investment.”
– Jeff C.
Paragraph Detection & Analysis
The Grooper paragraph ranking engine looks at a document’s structure and intelligently groups words into paragraphs.
It then compares them against training samples to find the “best match,” and presents a recommendation list.

Paragraph Isolation
Indentions, double spacing, bullets, key phrases, line length, and many other factors must be considered to determine where each paragraph starts and stops.
Grooper provides an easy to configure console in order to tune paragraph detection settings for each project.

Lexical Analysis
Use the full power of Grooper data types to collect features from within each paragraph. These can be n-grams, entries from a lexicon, or a non-value feature count grouped by data types like: address, phone number, name, etc.
The analysis spans lines of text to ensure accurate multi-word feature collection regardless of line wrap.

Data Merge
Once the paragraphs with an ideal match are recognized, they are grouped together as a single paragraph for more NLP analysis or text export.
Process paragraphs that are not next to each other in the original document or are spread across multiple pages.
You do not have to struggle through tough problems in document processing and data capture. Improve data collection from natural language documents to get the data you need.
How Does Grooper Analyze Leases & Help with Legal Contract Review?
First, What is Contract Review?
Contract review is the process of meticulously reading a contract to understand the obligations and rights of a company or person signing it and, as a result, determining the associated impact.
Contract review is generally recognized as one of the most repetitive and most tedious jobs that junior law firm associates must perform. It is also expensive and an wasteful use of a legal professional’s skills.
So, How Does Grooper NLP and AI Make Contract Review So Efficient?
Lease and contract analysis is a classic use-case for automation. Abstraction used to be a very manual and time consuming process. Prior to NLP solutions like Grooper, a lawyer or data clerk’s job is to manually review hundreds of pages of contracts to find the relevant clauses or obligations stipulated in a contract. They then must identify the same data points in a document, such as:
- What are the effective or end dates of a contract
- Renewal terms
- Parties involved in contract
- Clause identification
Grooper data classification and extraction models automatically identify and extract key data and clauses from within contracts, saving hundreds of hours of manual work.
The NLP processing software is trained to look for modifications within addendums / exhibits and associate them with the main provision.
This speeds up analysis and ensures you are correctly interpreting the data. Learn more about how to intelligently analyze leases and contracts through natural language processing examples below:
Natural Language Processing Spatial Analysis
Pattern matching on its own is great for efficiently finding common values like dates, amounts, and phone numbers. But when multiple choices are found on a document, how will the system know which one is the best match?
The answer is spatial analysis. Each choice is ranked by analyzing the words and features nearby.
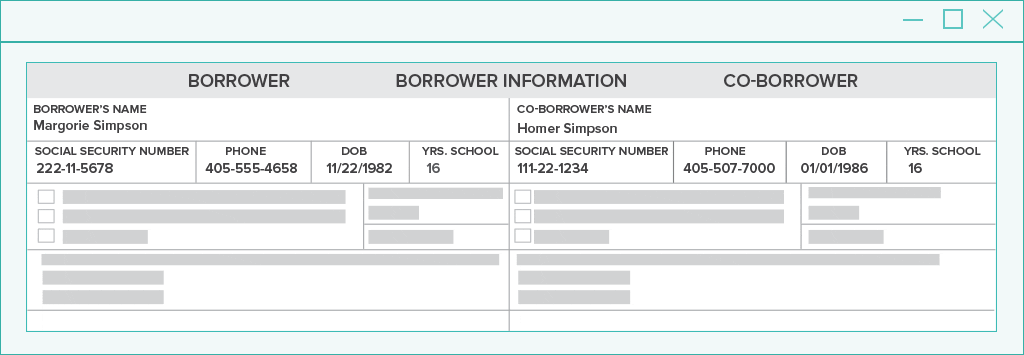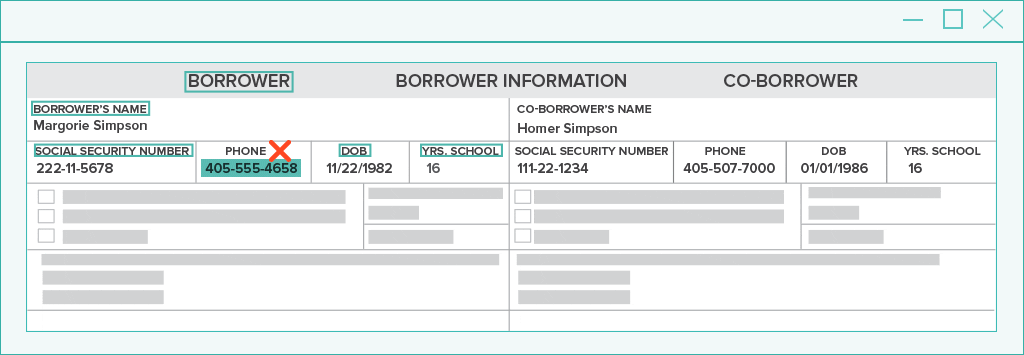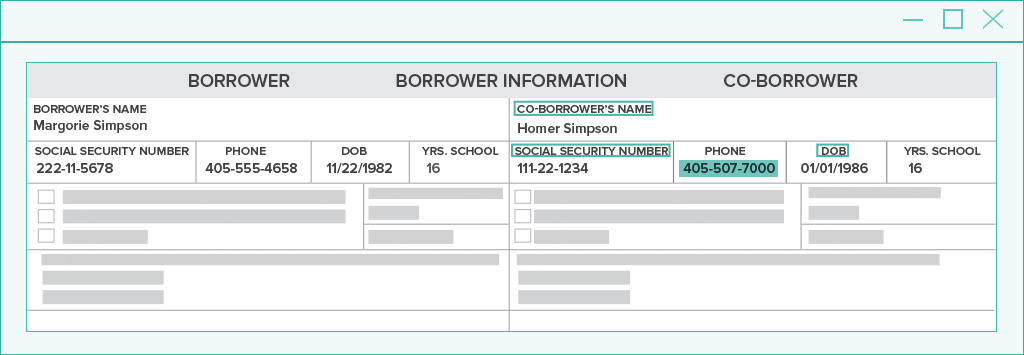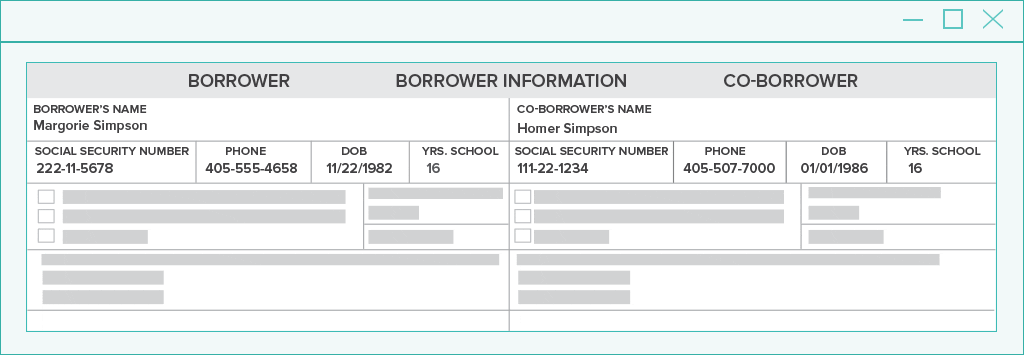
In the natural language processing example above, you will easily find the separate data that pertains to the borrower vs. co-borrower through radial spatial NLP analysis.
Label/Value Pairs
In structured documents, most data is recorded in label/value pairs. This means that a value has a corresponding label somewhere on the page that tells its meaning.
And field labels are generally written above and/or to the left of the value they define.
Grooper ranks possible values by looking spatially in one or more general directions and provides a confidence level percentage.
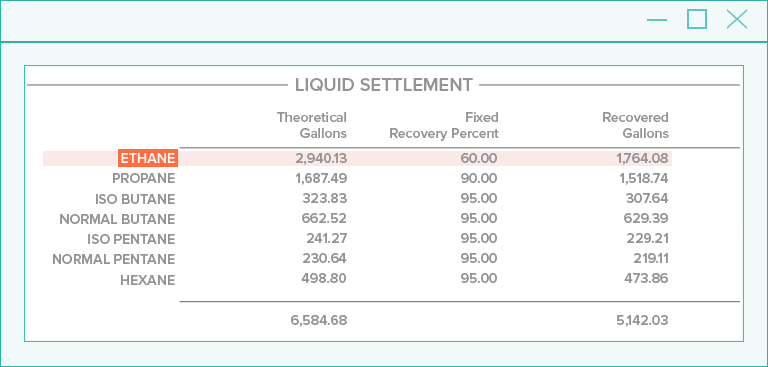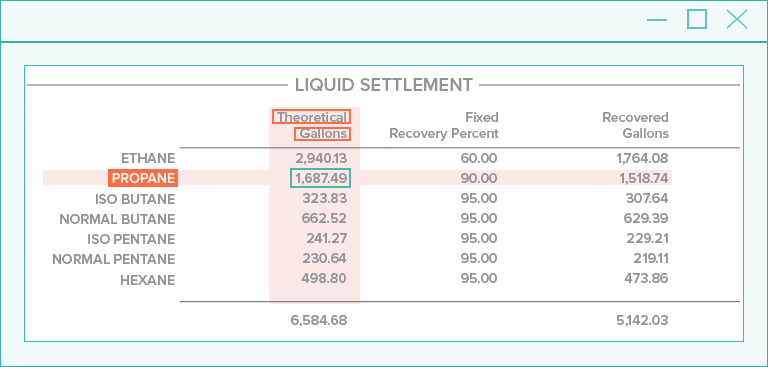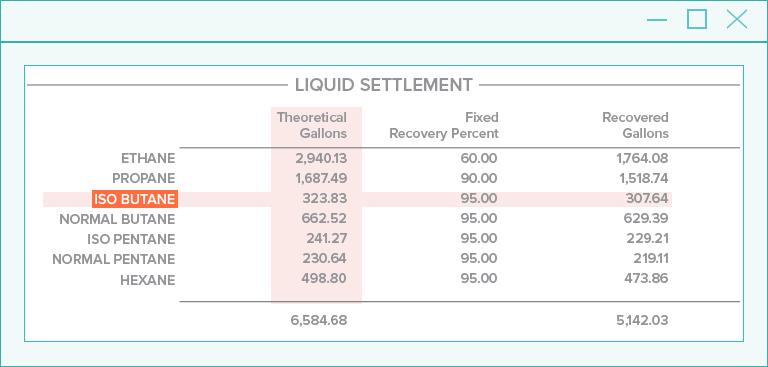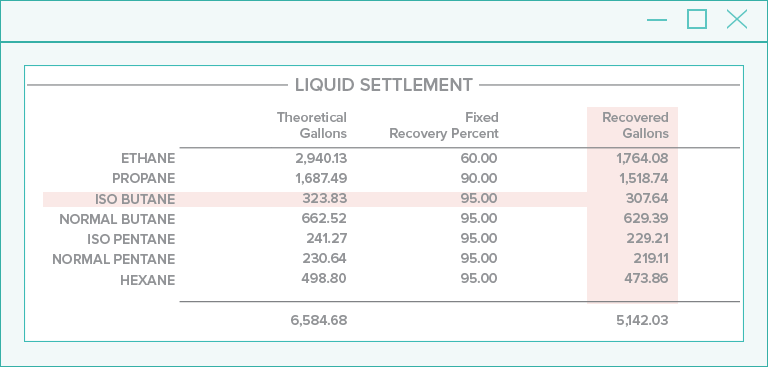

Radial Analysis and Geotagging
Considering the nearby words, and also the direction each word is located in relation to the candidate, leads to better accuracy identifying field values from documents.
Geotagging increases this, and it allows for filtering features based on direction as a simple way to remove features not likely to define a value.
